
escrito porCésar Aparicio
Últimamente se ha puesto de moda, otra vez, hablar sobre los efectos en el posicionamiento mediante la manipulación del CTR en los resultados de búsqueda. Podemos encontrar infinidad de experimentos realizados por SEOs, en los que se publican mejoras en el posicionamiento de determinadas landing pages. Muchos de estos experimentos (no todos, aclaro) no están correctamente realizados. Es por esto que los resultados en muchas ocasiones están viciados y no son reflejo objetivo de la realidad. Vamos a usar las matemáticas para explicar el modelo y ver qué sucede, abstrayéndonos de algo tan común en el mundo del SEO (y en los razonamientos en la vida en general) que son los supuestos infundados. Seré conciso y haré un artículo corto.
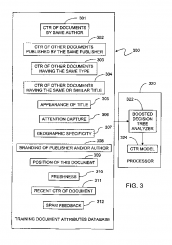
Primero: el CTR para determinados atributos (palabras clave, snippets, landing pages) se puede predecir aun sin tener o teniendo apenas datos históricos para ésos atributos. Es decir, no creamos que el motor de búsqueda necesita demasiados datos para saber cuál es el CTR que, por ejemplo» una landing tendrá, indiferentemente del lugar que ocupe. Esto es nuevo, para muestra un botón, de tantos que hay: Click through rate prediction system and method.
Segundo: Has de tener presente el método estadístico de estimación en máxima verosimilitud. Básicamente, la media y la varianza se pueden estimar con muy pocos datos de una población y traspolarlos para comprobar cuál es el resultado (CTR en nuestro ejemplo) más verosímil. Es decir, de antemano saber qué CTR es el mas verosímil (el dato más «probable» del modelo dado). Aquí un ejemplo.

Algunos ejemplos de cómo estimar el CTR de un atributo en función de otros datos
Juntando el primer y el segundo punto. A penas se necesitan datos para poder saber de antemano qué CTR tendrá un atributo. Si a esto le sumamos, que podemos calcular, como decía con muy pocos datos, cuál será el CTR más verosímil para una atributo. Entonces la manipulación del CTR fuera de unos parámetros establecidos previamente (mediante métodos estadísticos) es detectable. Del mismo modo que no lo sería, si dicha manipulación se mantiene dentro de los «márgenes» (desviaciones) establecidas por el método de máxima verosimilitud.
En definitiva, si la manipulación del CTR coincide con el modelo de clicks estimados para un atributo, detectar la «trampa» es difícil. Sin embargo, manipular el CTR y esperar que esta manipulación se mantenga dentro de los márgenes establecidos por el modelo, es más complicado aún.