
Como en la vida en general, es más fácil tener claro qué no queremos en nuestro futuro a qué queremos. Con el contenido sucede algo similar, es más fácil reconocer uno malo que uno bueno. Pero, ¿cómo podemos saber que un contenido es malo? Hay varios grupos de contenido de baja calidad o mala calidad. Los veremos a lo largo de artículo y también cómo resolver los problemas que provocan. Los principales son:
¡Vamos al tema! Tener contenido duplicado NO significa tener una penalización per se pero sí puede provocar pérdidas masivas de tráfico y problemas de todo tipo. ¿Por qué los problemas de contenido sabemos, entre otros, que no son una penalización? Porque no lastran el proyecto ad infinitum (otra locución latina en un mismo párrafo; stuffing latino), una vez que los resolvemos, al poco tiempo (habitualmente) se recupera el tráfico perdido.
Mayor contenido duplicado implica mayor probabilidad de crear patrones en un sitio web. Si usamos un determinado CMS y Google determina que una URL está mal o aglutina contenido malo, probablemente todas las URLs generadas en ese CMS estarán mal pues siguen el mismo patrón de errores (por ejemplo, problemas con etiquetas). Como los problemas de contenido son difíciles de detectar, podríamos creer que nuestro sitio web está bien pero que el nicho es muy complicado o la competencia es muy fuerte y eso nos provoca caídas de tráfico o nos impide subir. Creemos que es el nicho pero no, somos nosotros. Por eso, lo más importante es: detectar el problema y ponerle solución. El contenido de baja calidad (duplicado, etc.) no solo nos puede hacer perder tráfico sino que nos impide ganarlo… podríamos llamar a esto: El coste de oportunidad del contenido de baja calidad.
¿Qué debemos hacer si tenemos contenido duplicado?
Reconocimiento de contenido duplicado (o de baja calidad):
Lo primero para resolver un problema, es saber que se tiene (filosofía de botica). Por tanto, tenemos que plantearnos algunas cuestiones:
Tener muchos contenidos iguales o muy similares en nuestro sitio web, nos puede acarrear un problema de posicionamiento que solventaremos reduciendo la cantidad del contenido pernicioso. En cambio, cuando los problemas son de thin content lo que podemos hacer es enriquecer ese contenido.
¿Qué es el contenido de mala calidad?:
Ejemplos habituales de contenido de mala calidad:
Para responder a algunas búsquedas, siempre será mejor tener una sola URL que muchas.
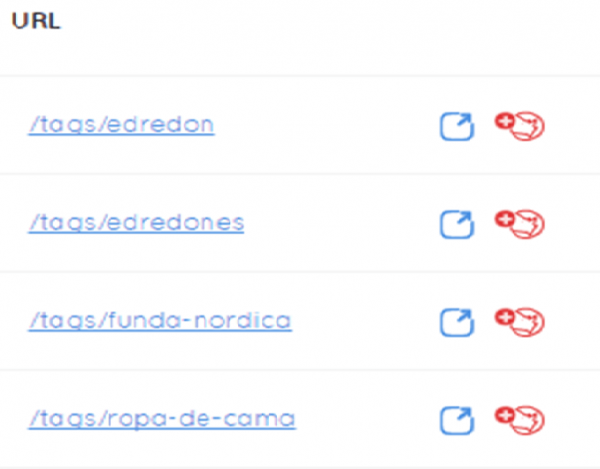
En este ejemplo, /edredon, /edredones, /funda-nordica y /ropa-de-cama, nos presentan un contenido igual o muy similar, lo que puede generar patrones que ocasionen problemas. Crear URLs con diccionarios e intentar solapar todas las queries con URLs iguales, ¡Mal!
En un caso como este, veremos qué URL es la que tiene más tráfico (en general), para mantener sólo esa. Si las otras tienen tráfico y enlaces haríamos una redirección 301 a la URL que queremos conservar. También será más positivo que exista una sola página a la hora de conseguir enlaces, ya que solamente serán necesarios para una URL (unifica y vencerás).
Los problemas de contenido pueden afectar a nivel del contenido principal, el suplementario o los anuncios.
Google funciona con patrones, usa machine learning (desde octubre de 2015 públicamente). Aprende mediante un montón de ejemplos con los que entrena a sus algoritmos. Tener una única URL con muy poco contenido o contenido de baja calidad no es un problema (y suele ser muy común en la páginas de contacto, quiénes somos, etc…), pero cuando tenemos muchas URLs así (contenido escaso y de baja calidad), se está generando un patrón redundante en el sitio, eso sí se consideraría thin content y habría que tomar medidas (estas medidas sobre thin content las veremos en un ejemplo más adelante).
– Textos de URL duplicados:
Si tenemos dos URLs distintas con el mismo contenido (o muy similar), Google entiende, por ejemplo, que le hacemos perder el tiempo rastreando dos veces lo mismo. Para darnos cuenta de que tenemos ese problema y poder solucionarlo podemos utilizar un excel y abrir todas las URLs e ir comparando a ojo tras abrirlas en texto plano o podemos usar Safecont, esperar un rato y que nos diga cuales son las URLs indexables de nuestro sitio que tienen contenido duplicado y cuáles son más peligrosas para nuestro posicionamiento para así atacar el problema con efectividad y rápido.
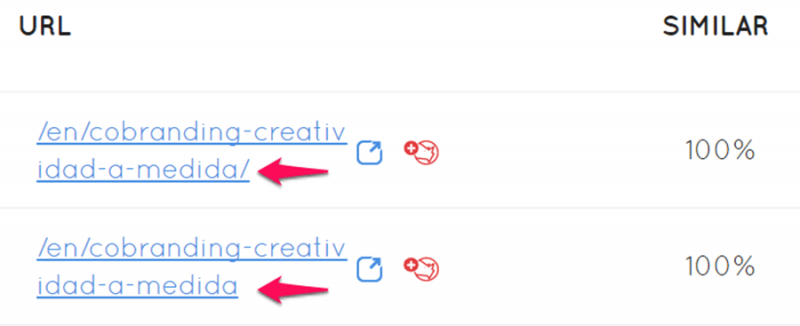
El ejemplo de arriba era un problema en el sitio web de Kukuxumusu visto con Safecont. Existía el mismo contenido en la URL con barra / y sin barra. Este tipo de situaciones son muy típicas: URLs repetidas con www. o sin ellas, con https o con http. La solución: redirección.
– URLs generadas por IDs, parametrizadas, etc:
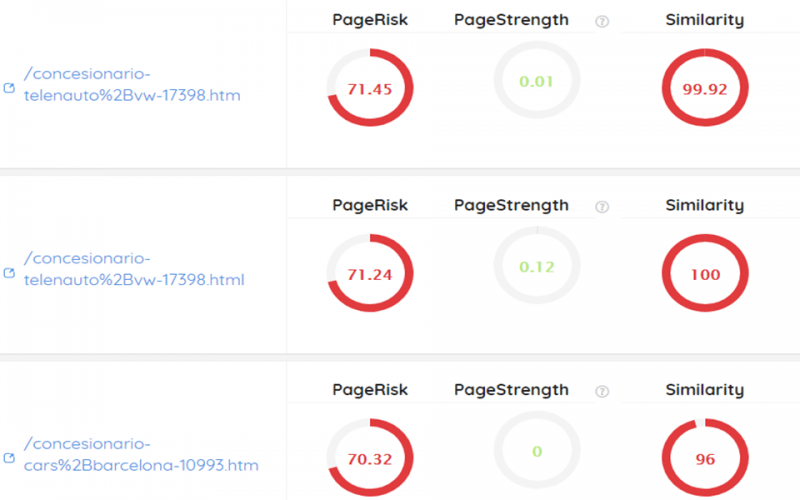
Las URLs con parámetros dan muchísimos problemas. En la imagen superior se pueden observar problemas de similaridad de contenido (Similarity) y riesgo de las páginas (PageRisk). Si tenemos un sistema de generar URLs, y se están generando mal, probablemente nos las va a hacer mal a lo largo de todo el sitio. Son problemas, por tanto, recurrentes. No indexar este tipo de URL es primordial (un ejemplo típico sería indexar las búsquedas del sitio).
– Thin content:


Ejemplo de thin content extraído con Safecont del sitio web de Moz. Las URLs anteriores están vacías de contenido. Son unas URLs que no hacen nada, no tienen contenido y están lastrando la arquitectura de todo el sitio web. ¿Qué hacemos? Borrarlas. Porque esas URLs que no aportan nada están evitando que otras del sitio posicionen bien.
– Boiler-plate:

Ejemplo de dos fichas creadas en las que sólo se ha cambiado el nombre y la fecha. Este tipo de contenido duplicado es muy típico en los ecommerce con las fichas de producto (mismo producto en colores diferentes y fichas idénticas cambiando algún dato). Esto es punible a ojos de Google. Recordamos que un mayor contenido duplicado implica mayor probabilidad de crear patrones en un sitio web.
Importante: relacionar arquitectura y contenido para solventar penalizaciones y optimizar los sitios web. La arquitectura y el contenido siempre van de la mano.

Un ejemplo de lo que pasa cuando limpias tu sitio de contenido de baja calidad:
Ejemplo de arquitectura deficiente (sacado con Safecont) de un ecommerce con 10 niveles de profundidad.
Como el contenido duplicado no es una penalización, cuando resolvemos el problema, podemos volver a recuperar el tráfico rápidamente. Aquí debajo un ejemplo:

Ejemplo de problema de contenido en el que Google ataca solo algunos clusters de URLs, con lo que el tráfico del sitio baja un poco, con el paso del tiempo se ataca a otros clusters, etc, hasta que ha caído el tráfico de toda la web. Lo que se debió hacer era solucionar los problemas de contenido cuando fueron surgiendo.
En resumen, motivos del contenido duplicado:
Habrá que ver dónde está el problema y atajarlo desde ahí.
Por tanto:
Primero: saber si tenemos el problema y luego actuar sobre las páginas más peligrosas (o sobre los clusters de URLs más peligrosos que tienen el mismo patrón).
Segundo: los problemas suelen ser recurrentes. Seguramente, si tengo problemas de contenido, los tendré a lo largo de todo el sitio web.
Mantener los sitios optimizados y limpios es la clave para no recibir una penalización o caída considerable de tráfico.
¡Menos es más!
